Who should read this article: All users
Voiso text-to-speech (TTS) supports Speech Synthesis Markup Language (SSML) to enable you to enhance the speech synthesis for voice messages.
Introduction
You can use Speech Synthesis Markup Language (SSML), a W3C standard XML-based markup language for speech synthesis applications, to enhance Voiso's voices with inflection, breath, and cadence. This allows you to adjust phrasing, emphasis, and intonation, creating natural-sounding voices that engage your contacts when they call into your contact center. Craft synthesized text-to-speech messages to convey the precise meaning and intent you want to impart.
Refer to Supported SSML tags for some examples of how you can use SSML in Voiso Flow Builder.
Reserved characters
SSML has five reserved characters that you cannot use without escaping them by using an escape code. If you need to use one of the characters, listed in the table below, replace the character in your message with the escape code. Fortunately, in spoken text, these characters are rarely used.
| Name | Character | Escape code |
|---|---|---|
| quotation mark (double quotation mark) | " | " |
| ampersand | & | & |
| apostrophe or single quotation mark | ' | ' |
| less than sign | < | < |
| greater than sign | > | > |
For example: Our organization's goal is to provide you with the best possible service!
How to use SSML tags
Most of the SSML tags are available for standard Amazon Polly voices. Refer to Supported SSML tags for the latest list of SSML tags that you can use with your messages.
To use a tag when you are composing a read-aloud voice message, make sure you enclose the tag in angle brackets like this:
<emphasis level="strong">
Close the tag with the same tag, but include the forward slash character like this:
</emphasis>
Putting it all together, it would look like this:
We have a <emphasis level="strong">limited time offer</emphasis> for you this week.
Here is another example with the same sentence, first without SSML tags, then with SSML tags.
Check out what it sounds like:
<speak>
<p>We have a limited time offer for you this week!
N'est-ce pas magnifique ?</p>
<p>We have a limited time offer <break strength="medium"/>
for <emphasis level="strong">you</emphasis>
<prosody rate="x-fast">this week</prosody>!
<lang xml:lang="fr-FR">N'est-ce pas magnifique ?</lang></p>
</speak>
Supported SSML tags
Amazon Polly Standard voices support many SSML tags that you can use to modify the speech patterns of your synthesized voice messages. Refer to Supported SSML tags for the latest information. Use the tags described in this section to customize your text-to-speech messages.
Break (adding a pause)
Use the <break/> tag to add a pause in your spoken text. Refer to Adding a pause for details about the time and strength attributes that you can use to define how long to pause while speaking.
Emphasis
Use the <emphasis>x</emphasis> tag pair to alter the speaking rate and volume of one or more words. The <emphasis> tag uses the level attribute to change how loud and fast your text is spoken. Refer to Emphasizing words for details about the level attribute.
Lang (language)
Use the <lang xml:lang="xx-XX">x</<lang> tag pair to tell the text-to-speech feature that the words between the tags should be spoken in a specific language instead of the language associated with the voice you are using.
The xx-XX refers to standardized language codes, such as es-MX for Spanish-Latin American (Mexican). Refer to Available Standard voices for a list of supported language codes.
Refer to Specifying another language for specific words for details about using the xml:lang attribute.
P (paragraph pause)
The <p>x</p> tag pair can be used just like in regular HTML to make paragraph breaks in your text. Text-to-speech adds an extra long pause between the text you enclose in these tags. These tags make speech sound more natural by preventing all your text from running together. Refer to Adding a pause between paragraphs for more details.
Phoneme (phonetic pronunciation)
Use the <phoneme alphabet="x" ph="y">x</phoneme> tag pairs to adjust the pronunciation of specific words. This feature enables you to customize the pronunciation of words to match local dialects. Text-to-speech gives you two phonetic alphabets to choose from. Refer to Using phonetic pronunciation and Phoneme and Viseme Tables for Supported Languages for all the details .
The following example demonstrates how to localize the pronunciation of "pecan", a word that has strong regional variation.
<speak>
<p> Examples of the International Phonetic Alphabet.</p>
<p>You say, <phoneme alphabet="ipa" ph="pɪˈkɑːn">pecan
</phoneme>. </p>
<p>I say, <phoneme alphabet="ipa" ph="ˈpi.kæn">pecan
</phoneme>.</p>
<p> Examples of the Extended Speech Assessment Methods
Phonetic Alphabet.</p>
<p>You say, <phoneme alphabet='x-sampa' ph='pI"kA:n'>pecan
</phoneme>.</p>
<p>I say, <phoneme alphabet='x-sampa' ph='"pi.k{n'>pecan
</phoneme>. </p>
</speak>
Prosody (volume, rate, pitch, and duration)
Use the <prosody x="y">x</prosody> tag pair and the volume, rate, pitch, amazon:maxduration attributes to finely control how loud or soft, fast or slow, and high or low the spoken text sounds.
Refer to Controlling volume, speaking rate, and pitch and Setting a maximum duration for synthesized speech for all the ways this tag pair can be used to add variation in the way that words or phrases are spoken. Prosody helps ensure that the voices sound less robotic.
S (sentence pause)
Use the <s>x</s> tag pair to add a slight pause between two blocks of text. The pause added by the <s> tag is slightly shorter than the pause added by the <p> tag. Use these two tag pairs together to add variation in the cadence of your spoken text. Refer to Adding a pause between sentences for a description of the effects of this tag pair.
Say-as (for special word types)
Use the <say-as interpret-as="x">x</say-as> to specify how you want numbers, dates, times, addresses, and phone numbers to be spoken. Refer to Controlling how special types of words are spoken for a list of the values supported for the interpret-as attribute.
Sub (for acronyms and abbreviations)
Use the <sub alias="x">x</sub> tag pair to specify how acronyms and abbreviations in your text messages are spoken. For example, if you are talking about the European Space Agency (EAS), by convention, the acronym ESA is pronounced as "ee-sa" instead of E.S.A.
<speak>
<p>ESA</p>
<p><sub alias="ee-sa">ESA</sub></p>
</speak>
Refer to Pronouncing acronyms and abbreviations for other examples of how to use this tag pair.
W (parts of speech)
Use the <w role="x">x</w> pair to interpret the pronunciation of words depending on the part of speech they comprise. For example, in English, the word "read" is pronounced differently, depending on whether it is a present-tense verb or a past-tense verb. The English word "bass" can mean a fish or a low musical tone. The <w> tag pair enables you to specify which pronunciation to use for these words.
Amazon Polly maintains a list of default (DEFAULT) and alternative pronunciations (SENSE_1) of words that have multiple pronunciations. If text-to-speech is not pronouncing a word the way you intend, try using the role="amazon:SENSE_1 attribute values to hear alternative pronunciations, for example, when you want to talk about the bass fish, use role="amazon:SENSE_1.
<speak>
<p>Do you play bass?</p>
<p>Do you like to fish for <w role="amazon:SENSE_1">bass</w>?</p>
<p>After I <w role="amazon:VBD">read</w> the first Game of
Thrones book by George <say-as interpret-as="rr-martin">R. R. Martin</say-as>,
I immediately wanted to <w role="amazon:VB">read</w> all the rest.</p>
</speak>
Here is a list of all the English words that have two different pronunciations:
- Attribute (a characteristic vs. to ascribe)
- Bass (fish vs. low sound)
- Bow (to bend vs. ribbon)
- Close (near vs. to shut)
- Compact (small vs. an agreement)
- Content (satisfied vs. material in a document)
- Contest (a competition vs. to challenge)
- Desert (arid land vs. to abandon)
- Lead (to guide vs. a type of metal)
- Minute (sixty seconds vs. very small)
- Object (a thing vs. to oppose)
- Project (a plan vs. to throw forward)
- Read (present tense vs. past tense)
- Record (to capture audio vs. a vinyl disk)
- Tear (rip vs. liquid from the eye)
- Wind (moving air vs. to twist)
Refer to Improving pronunciation by specifying parts of speech for more information about the <w> tag.
Amazon:breath (the sound of breathing)
When humans speak, we first breathe in, then breathe out as we speak. Synthesized voices do not do this naturally which is why they can sound robotic. Amazon Polly lets you add the sound of breathing to your spoken text with the <amazon:breath/> and <amazon:auto-breaths>x<\amazon:auto-breaths> tags.
Manual breaths
The <amazon:breath/> tag lets you insert the sound of a breath at a specific point in the text. You can use the duration attribute to specify how long the breath should be and the volume attribute to specify how loud or soft the breath is.
<speak>
<p>Sometimes you want to insert only <amazon:breath duration="medium" volume="x-loud"/>a single breath.</p>
<p>Sometimes you need <amazon:breath/>to insert one or more average breaths <amazon:breath/> so that the
text sounds correct.</p>
<p><amazon:breath duration="long" volume="x-loud"/> <prosody rate="120%"> <prosody volume="loud">
Wow! <amazon:breath duration="long" volume="loud"/> </prosody> That was quite fast. <amazon:breath
duration="medium" volume="x-loud"/> I almost beat my personal best time on this track. </prosody></p>
</speak>
Refer to Adding the sound of breathing to learn about how to control the breath sound.
Automatic breathing
The <amazon:auto-breaths>x</amazon:auto-breaths> tag pair lets the text-to-speech feature add automatic breathing to your spoken messages. You can control the volume, frequency, and duration of breaths using the volume, frequency, and duration attributes. Refer to Adding the sound of breathing for information about the values supported for these attributes.
<speak>
<amazon:auto-breaths>Voiso's <prosody rate="fast">
text-to-speech <w role="amazon:SENSE_1">feature</w></prosody> lets you compose
messages using text and SSML
that are spoken to your contacts when they call your contact
center, saving you time and money.</amazon:auto-breaths>
</speak>
Amazon effects
The <amazon:effect> tag lets you control the quality of the audio by adding recording studio-style effects like dynamic range compression, softening (phonation), and timbre control. Use different attributes and values to gain greater control over how a voice sounds. Use these tags as a pair: <amazon:effect [attribute]="[value"]>x</amazon:effect>.
The name="drc" attribute and value can be added to apply a boost to the mid-range part of the audio stream. This is useful if you expect your contacts to be listening to your message in a loud environment, such as a car, a busy street, or a crowded room. Refer to Adding dynamic range compression for an explanation of how this effect works.
The phonation="soft" attribute and value can be added to make the voice sound softer. It is a subtle effect, but the softer voice can sound more friendly and personal than the normal voice. Refer to Speaking softly for an explanation of how this effect works.
The vocal-tract-length="x" attribute and value can be added to change the perceived size of the person speaking. Here's an example:
<speak>
<p>You can control the timbre of my voice by making minor
adjustments. <amazon:effect vocal-tract-length="+7%">
For example, by making me sound just a little bigger.
</amazon:effect><amazon:effect
vocal-tract-length="-7%"> Or, making me sound only somewhat
smaller. </amazon:effect></p>
</speak>
Refer to Controlling timbre for an explanation of how this effect works.
The name="whispered" attribute and value lets you change the spoken message to a whisper. Refer to Whispering for an explanation of how this effect works and how to use it with the <prosody> tag.
Testing your messages
You can use your Amazon Web Services (AWS) account to access Amazon Polly to test all your scripts and messages before using them in the Voiso Flow Builder. This means you don't have to grant Flow Builder access to the person creating your text-to-speech scripts. The scriptwriter can work in AWS to perfect the message using SSML and various voices. AWS can generate MP3 files of the voices, which you can share with your team for approval before implementing the scripts in Flow Builder.
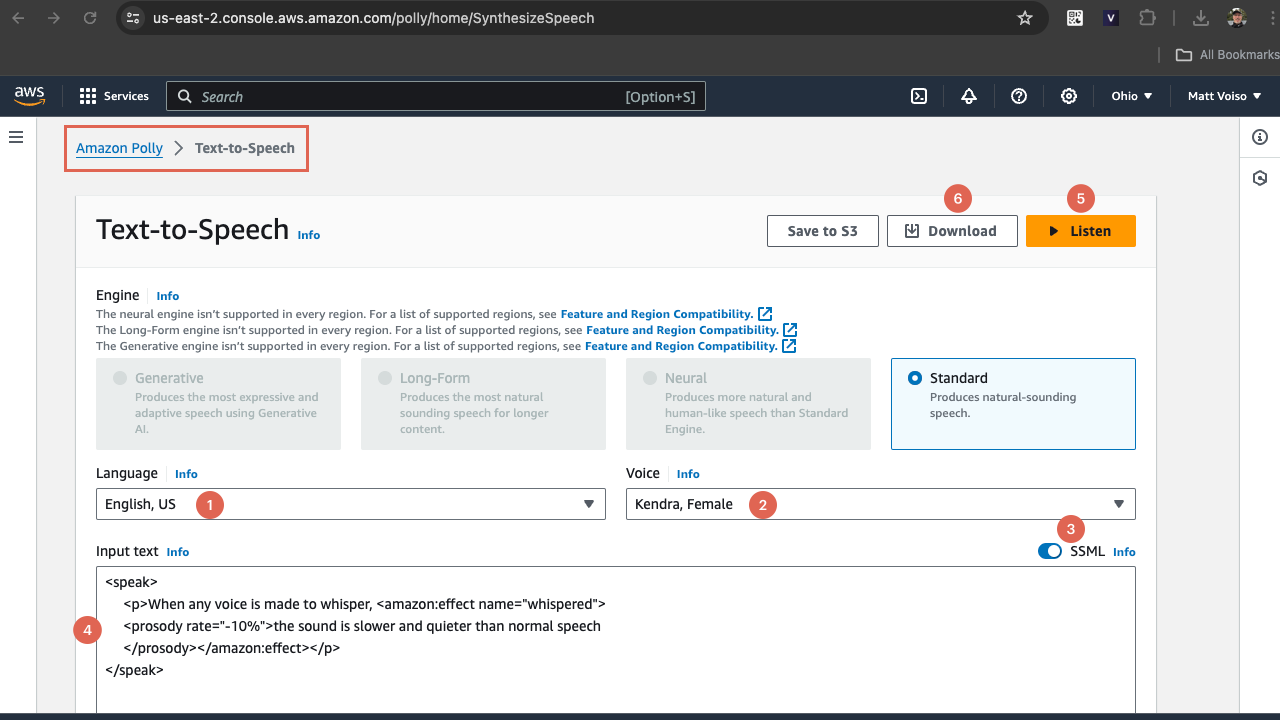
On the AWS Amazon Polly page, click Try Polly to navigate to the Text-to-Speech console, then follow these steps:
- Select your language.
- Select a voice.
- Enable SSML.
- Enter your text in the Input text field. Since you are using SSML, you must enclose the text in the
<speak>x<\speak>tag pair. Test out the various SSML tags as described above in this article. - Click Listen to hear what the message sounds like.
- When you are ready to share the message with your team for review and approval, click Download to download an MP3 to your computer.